
Click here for a PDF version of this post.

I joke that my job title should be software archaeologist because I often find myself resurrecting, not refactoring, code that dates to primitive and primeval eras. The language I’m typically hired to resurrect is APL. APL, the language with funny symbols, is a software vampire. People keep paying us to kill it, but no matter how many stakes we pound through its heart it keeps coming back.
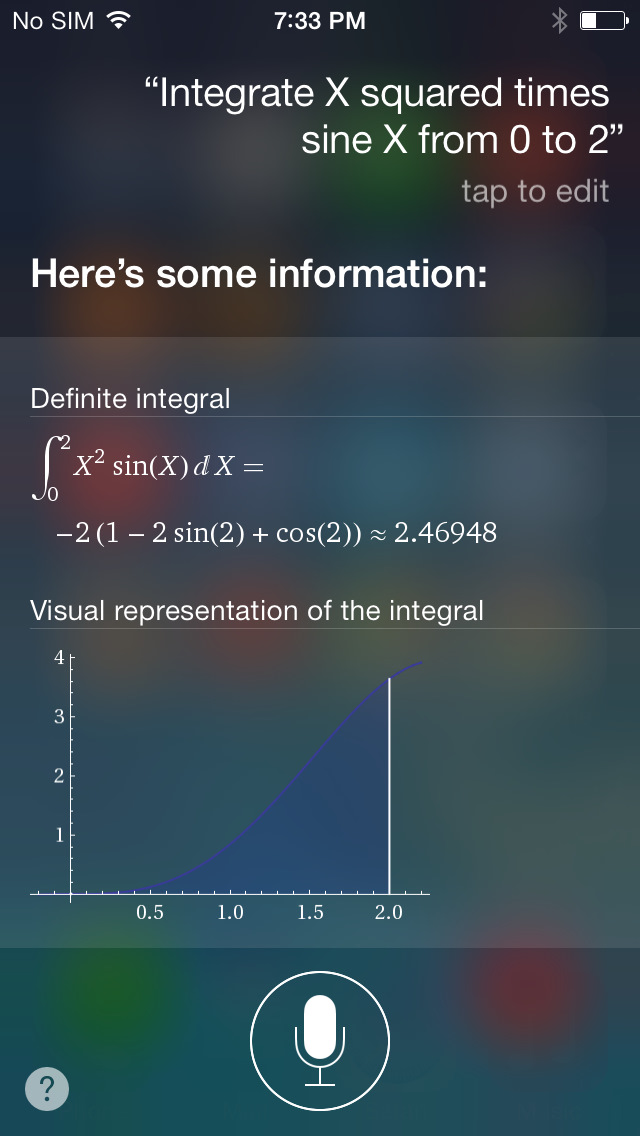
There are good reasons for this. APL embodies many timeless ideas and I’m confident that programming in the future will look a lot more like APL than many expect. If you doubt me just press the Siri button on your iPhone and ask, “Integrate X squared times sine X from 0 to 2.” What comes back has more of an APL than QWERTYUIOP flavor. Strange Unicode characters are creeping into many mainstream languages. This is a good thing because restricting programming to the miserly key sets of ancient typewriters was, is, and always will be a spectacularly bad idea. Ken Iverson deserves rich accolades for pointing this out more than fifty years ago and beating this drum incessantly during his lifetime. Iverson taught that notation is a tool of thought and that if you care about ideas you must care about how they are expressed. Why is this even remotely controversial?
The genius of APL continues to exert influence on many programming languages, but APL’s rise had little to do with its abstract notation and a lot to do with how it was implemented. APL was one of the first programming environments that nonprogrammers could use. It was the spreadsheet of the late 1960’s and 1970’s and just like spreadsheets of today a lot of utterly horrid, poorly structured, lame amateur messes were created with it. If you’ve ever cracked open a gigantic Excel model that looks like it was developed by a roomful of quarreling ADHD afflicted unionized chimpanzees then you know what the standard APL mess feels like. Many programmers blamed APL for this just like gun control advocates blame firearms for shootings. They argued that it would have been impossible to concoct such monsters in clean compiled languages like Pascal. “It wouldn’t even compile.” This is not even wrong. I’ve dealt with plenty of dreadful messes that do compile! The tool is always neutral; don’t blame the paintbrush for the painting.
Allowing rubes to code yields mountains of rubbish and the occasional ruby. It will shock many programmers to learn they are not the only smart people in the world. It turns out that nonprogrammers occasionally have good ideas and, miraculously, some of them can ably express their ideas in code. Before spreadsheets such user rubies congealed in APL where some still run. Part of my day job is extracting these precious stones from layers and layers of kluges, hacks, patch jobs, retro-fits and workarounds and recoding them in modern programming languages like C# and JavaScript.
Recently I recovered1 an ancient inverted file system embedded in the APL systems of my employer and rendered it in C#. This system uses the extension .dbi. I don’t know who created this system; the code is old. The most recent code comments date from the year 2000, but I am pretty sure that .dbi files predate component files in APL+WIN, formerly STSC APL, which pushes the design back to the 1980’s or earlier. I know many APL’ers check this blog. If any of you know who created the original .dbi APL code please leave a note.
Somehow this .dbi system survived unsupported, with few user complaints, for decades of daily use. How is this possible? Astonishingly, good ideas age well and the core .dbi idea is inverted data. Modern high-performance databases make heavy use of this method. Inversion is so effective that hoary old interpreted APL code still beats compiled and optimized ADO.Net when fetching large numeric vectors and tables.
Restoring the .dbi system was a two-step process.2 I first converted the APL system to J. I used J because it is a close relative of APL but not so close that you can cut and paste. Translating nontrivial APL to J forces you to understand the APL at the nit-bitty level. The translation to J also allowed me to fix the APL interface. The original system used global variables, rampant branches and other lamentable coding practices that C# will not abide. After matching the APL and J systems I then translated the J to C# and then rematched all three systems.
Comparing multiple systems is a very effective testing technique. I found bugs in all three systems. I fixed the J and C# bugs but left the original APL code unchanged. Software archaeology is a delicate field. You don’t “fix” old code just like you don’t correct errors in cuneiform tablets. Original and important program code belongs in museums with other significant cultural artifacts.
Original inverted file code probably belongs in a museum. This .dbi APL code is old, but it certainly derives from earlier programs so it’s not museum worthy. Even if it was the APL and C# .dbi systems belong to my employer. However, I am placing the J scaffold version, which matches the performance of the other systems, into the public domain. The script is available on GitHub. The .dbi system gets right down to bits in some cases and illustrates some J techniques for dealing with indexed binary inverted file data. Enjoy!
- .dbi files held many gigabytes of actuarially tuned data. Dumping them was not an option. We either had to convert to a new store or produce a component that could read old data in new systems.↩︎
- Restoring old code is somewhat like restoring old pictures. When working on old pictures you’re always tempted to improve them. With pictures you usually have a choice. This may not hold for old code. Changes in software may force updates.↩︎


Seem to remember Borland’s Database Explorer using the .DBI extension. Or maybe intermediate output from the Perl DataBaseInterface module? I did a little APL coding at the bit level on a 16K 5100 (http://www.classiccmp.org/dunfield/ibm5100/index.htm) 36 years ago to maximize variable usage and minimize tape reads. I appreciate your vampire reference above!
Thanks for your note. I didn’t know that .dbi files might have been used outside of APL contexts. Certainly the code I dealt with makes APL specific assumptions that required some work in C#.